
Meta 开源 Sapling 客户端,推动 monorepo 模式发展

1. Sapling 是什么?
Facebook Meta 悄悄 发布 新的版本管理工具 - Sapling 。网站首页打出 "A Scalable, User-Friendly Source Control System" 的 Slogan , 直击当前最普遍使用的版本管理工具 Git 的痛点。
Git 作为全世界开发者都在使用的版本管理工具,也是有一定学习曲线。 当然如果知道 clone、pull、commit 和 push 四个命令就可以完成日常 90% 以上的工作,所以少有人知道 Git 版本管理核心是 Snapshot ,很多人错误的以为 Git 的逻辑是 diff 。 GitHub 这些年做出了很多努力帮助开发者使用 Git,像 LFS 协议 和它的实现就是一个突出的贡献。 GitHub 是通过自身的服务,降低 Git 的使用门槛,并形成了一个完备的生态系统 "绑架" "俘虏" 了开发者的心。 Sapling 是不是真的对开发者友好,我没有深入使用并没有发言权,目前我的研究方向是在版本管理工具的 "Scalable" 能力上。
谈起版本管理工具的 Scalable ,就要先讲 monorepo 的概念了。众所周知,"不存在" 的互联网三大巨头 Google、Facebook 和 Twitter 三家是采用 monorepo 模式,只是各家技术栈不同。
Google 的版本管理系统叫做 Piper ,在 Piper 的相关论文中提到截止到 2015 年已经存储了 9 百万个文件,使用了 86 TB 存储空间,估计现在存储的文件应该达到 billion 级别了。 Piper 是 Google 通过修改 Perforce 并把它构建在其强大的基础设施之上,实现了海量的单一代码仓存储能力,同时 Google 还有一个自己的客户端 CitC ,能够兼容 Git 在本地使用。
Facebook 的版本管理系统 Sapling 是在 Mercurial 的基础做了修改,使其能够支持 monorepo 模式的开发,此次开源的就是这个系统的客户端。 而 Twitter 公司是在 Git 的基础上做增强使其能够支持 monorepo 模式。对于 Facebook 和 Twitter 目前系统存储的容量少有公开的报道。
从 Sapling 的文档看,其存储逻辑、命令和使用方式已经是独立发展,我觉得可以和 Mercurial 一样,算作是一个独立的版本管理工具。期望 Meta 能尽快把配套的 服务端 开源,让我们一窥 Sapling 的真容。
2. Git、Mercurial 和 Sapling 底层存储逻辑的差异
当研究 Monorepo 的 Scalable 的问题时,我发现多数版本管理系统产生和发展都是在开源社区中。开源社区的代码仓库体量相对比较小,和任意一个中型公司的代码仓库相比都是几个数量级的差距。但是开源社区的另一个显著的特点就是分散性,贡献代码的开发者居住在世界各地,所以开源社区的版本管理系统的第一要解决的问题就是分布式。既要开发者本地有完整的版本可以进行开发,又要能够将本地的版本通过邮件、HTTP 等协议推送到远程的版本仓库中,这就是 Git 和 Mercurial 的 "产品" 思路。
这几年我从事开发和运营开源项目都是按照 "产品" 思路去考虑,发现这样容易看懂开源项目的本质。
要保证开发人员本地拥有完整代码,所以多数版本管理工具会采用文件系统,通过各种编码等方式来存储源代码文件。Git 把所有文件保存在 .git 目录,Mercurial 把保存在 .hg 目录。这两个目录都是隐藏的,所以开发者在开发的时候是看不到的。这两个目录中存储的是 Git 和 Mercurial 的版本管理元数据,包括文件的版本信息、文件的变更信息、文件的历史版本等等。当开发的时候,Git 和 Mercurial 会 checkout 一个指定版本的代码到 工作目录 ,所有的工作都这这个目录下进行,当开发完成后,再将这个目录下的代码提交到 Git 或者 Mercurial 的版本仓库中。
2.1 Git Internals - Content-addressable FileSystem
这里引用 Git Internals 这个视频的内容和图片,这个系列的视频是我看到讲解最清楚的教程。
Git 把开发者提交文件的二进制完整保存在一个 blob 对象中。 不论是添加新文件还是修改文件的部分内容,都会 全量 保存文件的二进制数据。 Git 对每个 blob 对象都计算 SHA1 值做为这个对象的 ID 。
Git 把一个或者多个 blob 对象的 ID 保存在一个 tree 对象中,同时还在 tree 对象中记录了这个文件的名字, tree 对象就是每次开发者新加、修改的文件 清单 。 Git 对 tree 对象计算 SHA1 值做为对象的 ID 。
Git 最后把 tree 对象的 ID 保存在 commit 对象中, commit 对象同时包含了提交的作者名字、邮件地址、提交时间、描述和 parent tree 等信息。 Git 对每个 commit 对象计算 SHA1 值做为对象的 ID 。
这样形成了一个 Git 版本管理的数据链路,如下图所示:
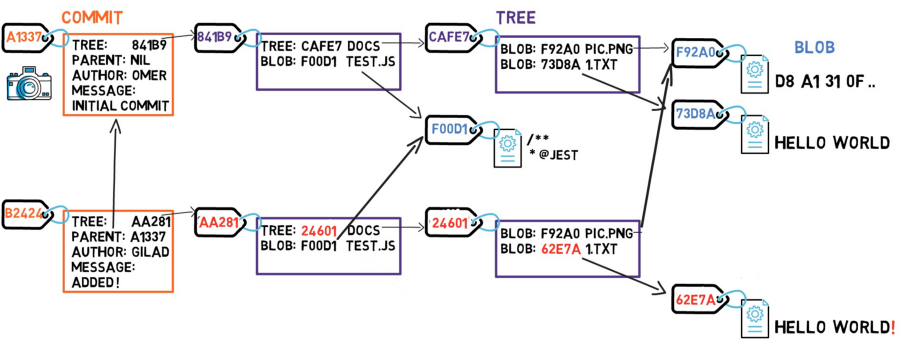
重点的是,每次文件修改都会保存一个新的 blob 对象,通过这样的 link 方式,可以形成一个完整的仓库的历史版本。
2.2 Mercurial Internals
Mercurial 在存储上和 Git 完全不同, Mercurial 使用 revlog 的格式来存储对象,每个文件的不同版本都保存中一个文件中。
$ hg debugindex .hg/store/data/src/pb.c.i
rev offset length base linkrev nodeid p1 p2
0 0 467 0 10 a7bdd2379025 000000000000 000000000000
1 467 168 0 12 692932a95c0d 000000000000 a7bdd2379025
2 635 173 0 15 f1d9cb4201e4 692932a95c0d 000000000000
3 808 476 0 17 d238a6113e4c f1d9cb4201e4 000000000000
4 1284 491 0 18 b71d299270a5 f1d9cb4201e4 000000000000
5 1775 470 0 19 4a7ebb32f962 b71d299270a5 d238a6113e4c
6 2245 64 0 20 6b99ca4dde14 4a7ebb32f962 000000000000
7 2309 177 0 21 33557d969679 d238a6113e4c 000000000000
8 2486 213 0 22 e4d67566afd0 6b99ca4dde14 33557d969679
9 2699 102 0 23 ab4bcfb966f8 33557d969679 000000000000
10 2801 384 0 24 86d19e47e6d0 e4d67566afd0 000000000000
11 3185 88 0 25 4969c00e0bc8 86d19e47e6d0 ab4bcfb966f8
revlog 格式定义两个文件,.d 文件包含实际的文件数据,.i 文件是索引文件,记录不同版本在 .d 文件中 offset ,使得检索起来速度更快。 在 .d 文件中即可以存储文件的完整内容(这跟 Git 的 blob 对象的逻辑是一样的),也可以存储和上一个版本的二进制差异(这与 Git 的 Pack 文件存储逻辑相通,关于 Pack 文件的格式请自行 Google 之)。为了提升检索速度,每隔一定版本 Mercurial 会保存一个全量文件的快照,这样版本回溯的时候就大大节省了时间。
对应 Git 的 tree 对象,Mercurial 也有类似的概念,叫做 manifest , manifest 保存了文件的名字和 revlog 的索引文件的对应关系,这样就可以通过文件名字来找到对应的 revlog 文件。
对应 Git 的 Commit 对象,Mercurial 使用的是 changeset ,也是包含了一次提交的各种信息。
虽然存储方式和 Git 完全不同,但是 Mercurial 也是可以形成一个完整的版本管理的数据链路。
.--------linkrev-------------.
v |
.---------. .--------. .--------.
|changeset| .->|manifest| .->|file |---.
|index | | |index | | |index | |--.
`---------' | `--------' | `--------' | |
| | | | | `-------' |
V | V | V `-------'
.---------. | .--------. | .---------.
|changeset|-' |manifest|-' |file |
|data | |data | |revision |
`---------' `--------' `---------'
我对 Mercurial 的研究不多,如果以上描述有错误请 TG 联系我,ID
genedna。
2.3 Sapling Internals
Sapling 采用了一个叫 IndexedLog 的格式来存储对象,这个格式是 Sapling 自己设计的,目的是为了提升 Sapling 的性能,解决 Mercurial 和 Git 的各种问题。 它的目标:
- O(log N) 查找,不需要重新打包以保持性能。这个主要是针对 Git 面对大仓库时需要把对象打包成 Pack 文件的问题,这样会导致查找性能下降。
- 通过哈希值插入,没有拓扑顺序限制。 这个主要是针对 Mercurial 的
.d文件是 append 的方式修改,无法在中间插入新的对象。
Sapling 的 IndexedLog 对应的是 Mercurial 的 revlog ,结构上采用了一个 log 文件和多个 index 文件的方式。log 文件对应 Mercurial 的 .d 文件,index 文件对应 Mercurial 的 .i 文件,但是 Sapling 有多种 index 。
- Index 是对应 Rust 的函数,是没有办法序列化使用,相当于应用在内存中的索引。
- Standalone Index 是相当于应用在磁盘上的索引,类似于 Rust 的
BTreeMap<Vec<u8>, LinkedList<u64>>结构,可以序列化和反序列化。
总结
从 Sapling 的介绍文章和文档来看,目前放出的只是一个客户端,如果面对大仓库的话,还差虚拟文件系统和服务端。虚拟文件系统的思路有点像微软解决 Git 超大仓库采用的方式;延迟下载 的逻辑其实 Git 也可以采用 Shallow Clone --depth=1 --single-branch --branch=<branch> 的方式获取 HEAD 指向的 Snapshot,而不是全部下载。
对于提交,不管是那种版本管理工具都对提交的内容进行了哈希,有的存储全量快照,有的存储二进制的差异。如果以全量快照的方式来看,哈希值是 Key ,提交的文件或者内容是 Value ,形成了一组唯一的 Key-Value。如果采用大型的分布式数据库对这些 Key-Value 对进行存储,那么就可以实现一个分布式的大型版本管理系统。其实 Google 的版本管理系统 Piper 正是采用这种逻辑将数据存储到它的全球一致性数据库 Spanner 中。
仅仅进行存储还不能解决我们生产中的问题,其中最主要的有两个:
- 对于 monorepo 需要采用 Trunk Based Development 的研发模型,这对很多公司都是不可想象的,尤其是是很多开发者已经习惯 GitHub PR 或者基于 Git Flow 的开发模型,同时也对研发管理、代码 Review、生产部署等带来巨大的冲击。
- 对于 monorepo 必须有一个超大型的 构建系统 进行支撑。Google 开源了 Bazel,Facebook 开源了 Buck,Twitter 开源了 Pants 。 没有这样大型的构建系统能力, monorepo 也是水中望月而已。
Sapling 的底层存储使用 Rust 开发,Mercurial 的底层存储也启动了 Rust 的改造计划,gitoxide 是目前最完善的 Rust 的 Git 客户端实现。 加上还不被大家所知晓的使用 Rust 开发,号称下一代版本管理工具的 Pijul,可以看到版本管理系统在用 Rust 重构底层存储的趋势,Rust 的明星项目有望会在这个领域脱颖而出。